「AI秘籍」系列课程:
- 人工智能应用数学基础
- 人工智能Python基础
- 人工智能基础核心知识
- 人工智能BI核心知识
- 人工智能CV核心知识
使用 DNN 和字符 n-gram 对一段文本的语言进行分类(附 Python 代码)

资料来源,flaticon:https://www.flaticon.com/premium-icon/cyborg_901032
语言识别是自然语言处理 (NLP) 问题中的一个重要步骤。它涉及尝试预测一段文本的自然语言。在采取其他操作(即翻译/情感分析)之前,了解文本的语言非常重要。例如,如果你使用谷歌翻译,你输入的框会显示“检测语言”。这是因为谷歌首先尝试识别你的句子的语言,然后才能翻译它。

语言识别有几种不同的方法,在本文中,我们将详细探讨其中一种方法。即使用神经网络和字符 n-gram 作为特征。最后,我们表明这种方法可以实现超过 98% 的准确率。在此过程中,我们将讨论关键代码,你可以在GitHub1找到完整的项目。首先,我们将讨论用于训练神经网络的数据集。
数据集
数据集2由 Tatoeba 提供。 完整数据集包含 328 种独特语言的 6,872,356 个句子。为了简化我们的问题,我们将考虑:
- 6 种拉丁语言:英语、德语、西班牙语、法语、葡萄牙语和意大利语。
- 长度在 20 到 200 个字符之间的句子。
我们可以在表 1 中看到每种语言的一个句子示例。我们的目标是创建一个可以使用提供的文本预测目标变量的模型。

我们在下面的代码中加载数据集并进行一些初始处理。我们首先过滤数据集以获取所需长度和语言的句子。我们从每种语言中随机选择 50,000 个句子,这样我们总共有 300,000 行。然后将这些句子分成训练集(70%)、验证集(20%)和测试集(10%)。
# read in full dataset
data = pd.read_csv(data_path + '/public_articles/sentences.csv',
sep='\t',
encoding='utf8',
index_col=0,
names=['lang','text'])
# Filter by text length
data = data[data['text'].str.len().between(20, 200)]
# Filter by text language
lang = ['deu', 'eng', 'fra', 'ita', 'por', 'spa']
data = data[data['lang'].isin(lang)]
# Select 50000 rows for each language
data_trim_list = [data[data['lang'] == l].sample(50000, random_state=100) for l in lang]
# Concatenate all the samples
data_trim = pd.concat(data_trim_list)
# Create a random train, valid, test split
data_shuffle = data_trim.sample(frac=1, random_state=100)
train = data_shuffle[:210000]
valid = data_shuffle[210000:270000]
test = data_shuffle[270000:300000]
# Check the shapes to ensure everything is correct
print(f"Train set shape: {train.shape}")
print(f"Validation set shape: {valid.shape}")
print(f"Test set shape: {test.shape}")
特征工程
在拟合模型之前,我们必须将数据集转换为神经网络可以理解的形式。换句话说,我们需要从句子列表中提取特征来创建特征矩阵。我们使用字符 n-gram(n 个连续字符的集合)来实现这一点。这是一种类似于词袋模型的方法,只不过我们使用的是字符而不是单词。
对于我们的语言识别问题,我们将使用字符 3-grams/ trigrams (即 3 个连续字符的集合)。在图 2 中,我们看到了如何使用 trigrams 对句子进行矢量化的示例。首先,我们从句子中获取所有 trigrams 。为了减少特征空间,我们取这些 trigrams 的子集。我们使用这个子集对句子进行矢量化。第一个句子的向量是 [2,0,1,0,0],因为 trigrams “is_”在句子中出现两次,“his”出现一次。

创建三元特征矩阵的过程类似,但稍微复杂一些。在下一节中,我们将深入研究用于创建矩阵的代码。在此之前,有必要对如何创建特征矩阵进行总体概述。所采取的步骤如下:
- 使用训练集,我们从每种语言中选择了 200 个最常见的三字母组
- 根据这些 trigrams 创建一个唯一 trigrams 列表。这些语言共享一些共同的 trigrams ,因此我们最终得到了 661 个唯一 trigrams
- 通过计算每个句子中每个 trigrams 出现的次数来创建特征矩阵
我们可以在表 2 中看到此类特征矩阵的示例。顶行给出了 661 个 trigrams 中的每一个。然后,每个编号行给出了我们数据集中的一个句子。矩阵中的数字给出了该 trigrams 在句子中出现的次数。例如,“eux”在句子 2 中出现了一次。
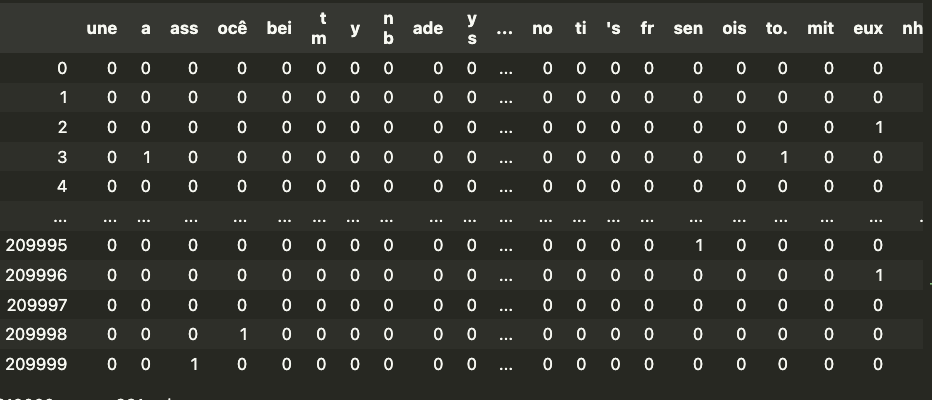
创建特征
在本节中,我们将介绍用于创建表 2 中的训练特征矩阵和验证/测试特征矩阵的代码。我们大量使用了SciKit Learn 提供的CountVectorizer包。此包允许我们根据一些词汇表(即单词/字符列表)对文本进行矢量化。在我们的例子中,词汇表是一组 661 个 trigrams 。
首先,我们必须创建这个词汇表。我们首先从每种语言中获取 200 个最常见的 trigrams 。这是使用下面代码中的*get_trigrams*函数完成的。此函数获取一个句子列表,并将从这些句子中返回 200 个最常见的 trigrams 的列表。
from sklearn.feature_extraction.text import CountVectorizer
def get_trigrams(corpus, n_feat=200):
"""
Returns a list of the N most common character trigrams from a list of sentences
params
------------
corpus: list of strings
n_feat: integer
"""
# fit the n-gram model
vectorizer = CountVectorizer(analyzer='char', ngram_range=(3, 3), max_features=n_feat)
X = vectorizer.fit_transform(corpus)
# Get model feature names
feature_names = vectorizer.get_feature_names_out()
return feature_names
在下面的代码中,我们循环遍历这 6 种语言。对于每种语言,我们从训练集中获取相关句子。然后我们使用get_trigrams函数获取 200 个最常见的 trigrams 并将它们添加到集合中。最后,由于这些语言共享一些共同的 trigrams ,我们得到了一组 661 个独特的 trigrams 。我们用它们来创建一个词汇表。
# obtain trigrams from each language
features = {}
features_set = set()
for l in lang:
# get corpus filtered by language
corpus = train[train.lang==l]['text']
# get 200 most frequent trigrams
trigrams = get_trigrams(corpus)
# add to dict and set
features[l] = trigrams
features_set.update(trigrams)
# create vocabulary list using feature set
vocab = dict()
for i,f in enumerate(features_set):
vocab[f]=i
然后,CountVectorisor 包使用词汇表对训练集中的每个句子进行矢量化。结果就是我们之前看到的表 2 中的特征矩阵。
# train count vectoriser using vocabulary
vectorizer = CountVectorizer(analyzer='char',
ngram_range=(3, 3),
vocabulary=vocab)
# create feature matrix for training set
corpus = train['text']
X = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
train_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
在训练模型之前,最后一步是缩放特征矩阵。这将有助于我们的神经网络收敛到最佳参数权重。在下面的代码中,我们使用最小-最大缩放来缩放训练矩阵。
# Scale feature matrix
train_min = train_feat.min()
train_max = train_feat.max()
train_feat = (train_feat - train_min)/(train_max-train_min)
# Add target variable
train_feat['lang'] = list(train['lang'])
我们还需要获取验证和测试数据集的特征矩阵。在下面的代码中,我们像对训练集所做的那样对 2 个集合进行矢量化和缩放。值得注意的是,我们使用了词汇表以及从训练集中获得的最小/最大值。这是为了避免任何数据泄露。
# create feature matrix for validation set
corpus = valid['text']
X = vectorizer.fit_transform(corpus)
valid_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
valid_feat = (valid_feat - train_min)/(train_max-train_min)
valid_feat['lang'] = list(valid['lang'])
# create feature matrix for test set
corpus = test['text']
X = vectorizer.fit_transform(corpus)
test_feat = pd.DataFrame(data=X.toarray(),columns=feature_names)
test_feat = (test_feat - train_min)/(train_max-train_min)
test_feat['lang'] = list(test['lang'])
探索 trigrams
现在,我们已经准备好了可用于训练神经网络的数据集。在此之前,探索数据集并建立一些直觉来了解这些特征在预测语言方面的表现会很有用。图 2 给出了每种语言与其他语言共有的 trigrams 数量。例如,英语和德语有 56 个最常见的 trigrams 是共同的。
我们发现西班牙语和葡萄牙语的共同 trigrams 最多,有 128 个共同的 trigrams。这是有道理的,因为在所有语言中,这两种语言在词汇上最相似。这意味着,使用这些特征,我们的模型可能很难区分西班牙语和葡萄牙语,反之亦然。同样,葡萄牙语和德语的共同 trigrams 最少,我们可以预期我们的模型在区分这些语言方面会更好。
建模
我们使用keras包来训练 DNN。模型的输出层使用 softmax 激活函数。这意味着我们必须将目标变量列表转换为 one-hot 编码列表。这可以通过下面的编码函数来实现。 该函数接收目标变量列表,并返回单次编码向量列表。 例如,[eng,por,por, fra,…] 将变为[[0,1,0,0,0,0],[0,0,0,0,1,0],[0,0,0,0,1,0],[0,0,1,0,0,0],…]。
from sklearn.preprocessing import LabelEncoder
from keras.utils import np_utils
# Fit encoder
encoder = LabelEncoder()
encoder.fit(['deu', 'eng', 'fra', 'ita', 'por', 'spa'])
def encode(y):
"""
Returns a list of one hot encodings
Params
---------
y: list of language labels
"""
y_encoded = encoder.transform(y)
y_dummy = np_utils.to_categorical(y_encoded)
return y_dummy
在选择最终模型结构之前,我进行了一些超参数调整。我改变了隐藏层中的节点数、epoch 数和批处理大小。最终模型选择了在验证集上实现最高准确率的超参数组合。
最终模型有 3 个隐藏层,分别有 500、500 和 250 个节点。输出层有 6 个节点,每个语言一个。隐藏层都具有 ReLU 激活函数,并且如上所述,输出层具有 softmax 激活函数。我们使用 4 个 epoch 和 100 的批处理大小来训练此模型。使用我们的训练集和独热编码目标变量列表,我们在以下代码中训练此 DDN。最终,我们实现了 99.57% 的训练准确率。
from keras.models import Sequential
from keras.layers import Dense
#Get training data
x = train_feat.drop('lang',axis=1)
y = encode(train_feat['lang'])
#Define model
model = Sequential()
model.add(Dense(500, input_dim=661, activation='relu'))
model.add(Dense(500, activation='relu'))
model.add(Dense(250, activation='relu'))
model.add(Dense(6, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#Train model
model.fit(x, y, epochs=4, batch_size=100)
模型评估
在模型训练过程中,模型可能会偏向训练集和验证集。因此,最好在未见过的测试集上确定模型准确率。测试集的最终准确率为 98.60%。这低于训练准确率 99.57%,表明发生了一些对训练集的过度拟合。
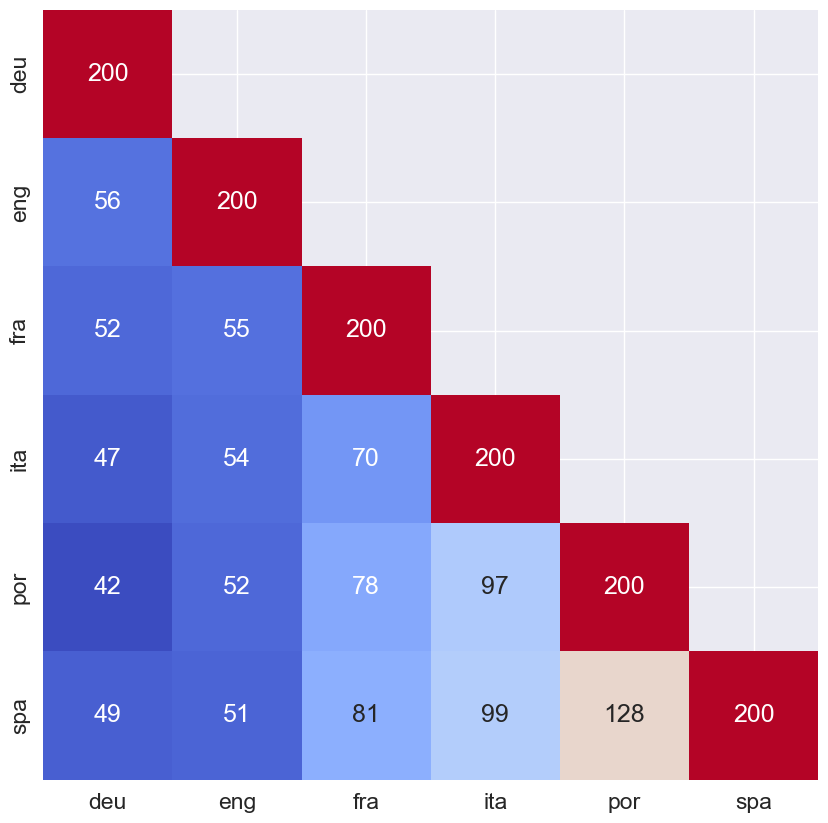
通过查看图 3 中的混淆矩阵,我们可以更好地了解模型对每种语言的表现。红色对角线表示每种语言的正确预测数。非对角线数字表示一种语言被错误预测为另一种语言的次数。例如,德语被错误预测为英语 5 次。我们发现,该模型最常将葡萄牙语混淆为西班牙语(78 次)或将西班牙语混淆为葡萄牙语(88 次)。这是我们在探索特征时看到的结果。
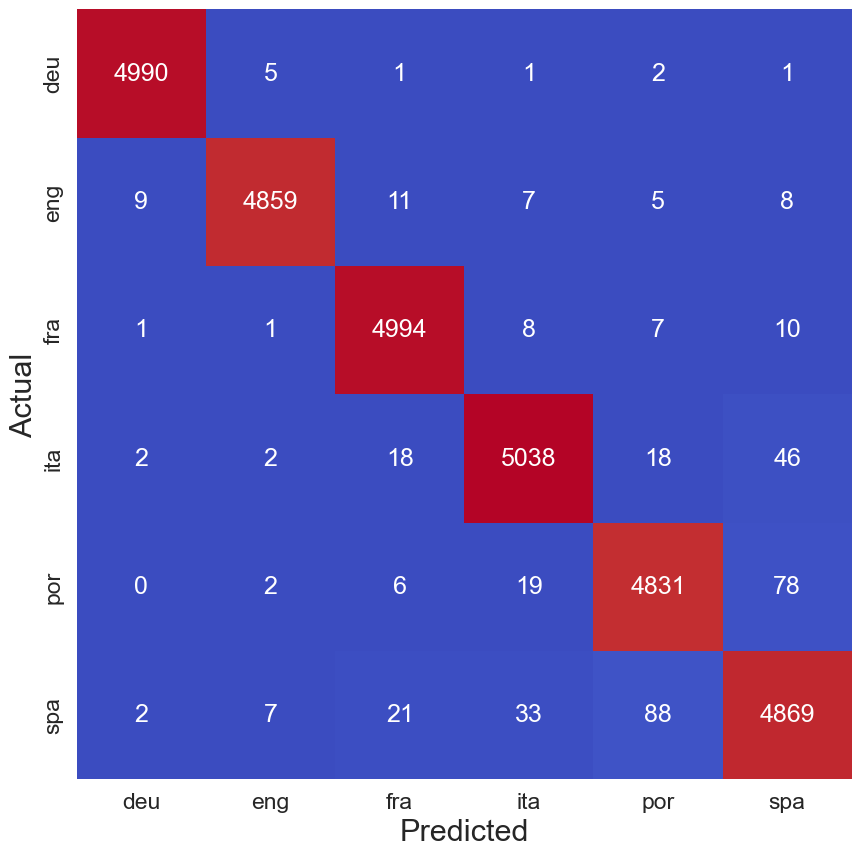
创建此混淆矩阵的代码如下所示。首先,我们使用上面训练的模型对测试集进行预测。使用这些预测语言和实际语言,我们创建一个混淆矩阵并使用 seaborn 热图对其进行可视化。
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
# x_test 和 y_test 已经定义,并且 model 是一个已训练好的 Keras 模型
x_test = test_feat.drop('lang', axis=1)
y_test = test_feat['lang']
# Use model.predict to get probabilities
predictions_prob = model.predict(x_test)
# Find the index of the highest probability for each sample
labels = np.argmax(predictions_prob, axis=1)
predictions = encoder.inverse_transform(labels)
# Ensure y_test is a 1D array
if y_test.ndim > 1:
y_test = np.argmax(y_test, axis=1)
# Accuracy on test set
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy}")
# Create confusion matrix
lang = ['deu', 'eng', 'fra', 'ita', 'por', 'spa']
conf_matrix = confusion_matrix(y_test, predictions)
conf_matrix_df = pd.DataFrame(conf_matrix, columns=lang, index=lang)
# Plot confusion matrix heatmap
plt.figure(figsize=(10, 10), facecolor='w', edgecolor='k')
sns.set(font_scale=1.5)
sns.heatmap(conf_matrix_df, cmap='coolwarm', annot=True, fmt='.5g', cbar=False)
plt.xlabel('Predicted', fontsize=22)
plt.ylabel('Actual', fontsize=22)
plt.savefig('../figures/model_eval.png', format='png', dpi=150)
plt.show()
最后,98.60% 的测试准确率仍有提升空间。在特征选择方面,我们保持简单,只为每种语言选择了 200 个最常见的 trigrams 。更复杂的方法可以帮助我们区分更相似的语言。例如,我们可以选择在西班牙语中很常见但在葡萄牙语中不太常见的 trigrams ,反之亦然。我们还可以尝试不同的模型。希望这对你的语言识别实验来说是一个良好的起点。
参考
茶桁的公开文章项目文件 https://github.com/hivandu/public_articles ↩︎
Tatoeba 数据集 https://downloads.tatoeba.org/exports/ ↩︎